|
Home Page
Six Transistor Cache
Investors
Launch Date
Contacts
Terms and Conditions
_________________________
|
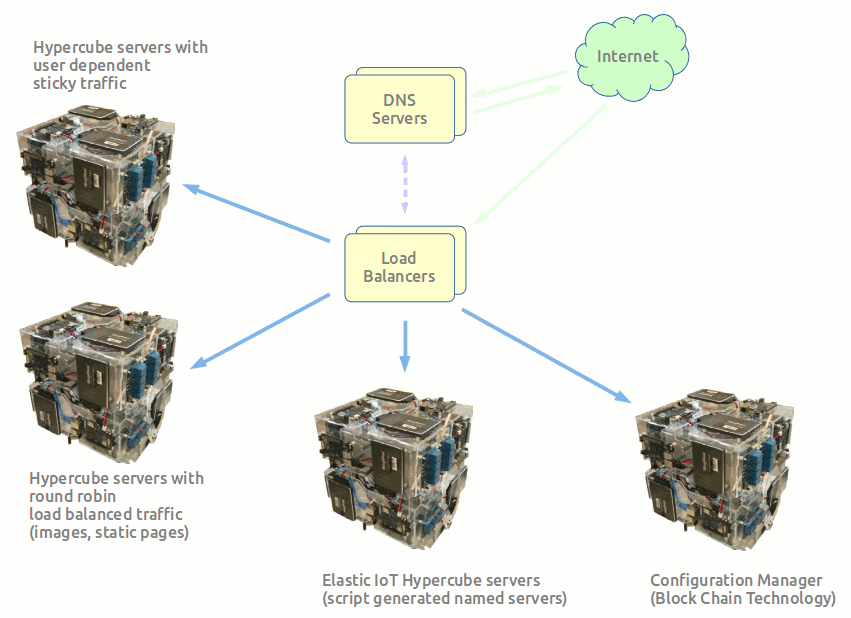
Micro Hypercube Data Center
Micro Hypercube Data Center scalable to suit IoT projects to mega scale projects
- The DNS servers working.
- Load balancing working.
- High availability working.
- Each micro Hypercube Data Center system consists of built in DNS servers that route traffic to load balancers which then route user dependent sticky traffic to dedicated servers, round robin load balanced traffic to image servers and static content servers, and elastic servers that are livened up on demand by scripts to service IoT devices, surges in traffic, and reconfigurable servers that reconfigure as customers come and go. The intention of scripts and text based configuration file is to change the DNS servers on the fly to give names to all elastic servers and IoT servers for developers with accounts on the system that then avoids having to hard code machine specific information.
- The configuration management we implement with proven tools for block chain technology. This is typical block chain entry:
previous_block_chain cc19c6c09cafe004db004ec10569ccb6bc859fd5874960897f558e1ef22eb8b4
domain ponytail.com # domain to access the servers - so the store servers become s1.uk.store.ponytail.com,
s1.us.store.ponytail.com and s1.cn.store.ponytail.com
countries
# Countries where the servers will be located - usually regional codes
# - but can be any letters other than countries - e.g. research, staging etc.
us
uk
cn
research
uk {
availability 3 # High availability is 2 more servers - default is 1
ha1 uk.ha_lupin # Optional server names otherwise default names ha1, ha2 etc
ha2 uk.ha_posh
ha3 uk.ha_ultimate
balance 5 # Load balancers is 2 or more servers - default is 1
lb1 uk.lb1.shop # Optional names of servers otherwise name is lb1, lb2 etc
lb2 uk.lb2.directory
lb3 uk.lb3.cart
lb4 uk.lb4.mysql
lb5 uk.lb5
servers 3 # additional servers - default is 1
s1 uk.store # default is s1.uk, s2.uk etc
s2 uk.statistics
s3 uk.reports
}
us {
availability 2 # High availability is 2 more servers - default is 1
ha1 us.ha_lupin # Optional server names otherwise default names ha1, ha2 etc
ha2 us.ha_posh
balance 4 # Load balancers is 2 or more servers - default is 1
lb1 us.lb1.shop # Optional names of servers otherwise name is lb1, lb2 etc
lb2 us.lb2.directory
lb3 us.lb3.cart
lb4 us.lb4.mysql
servers 1 # additional servers - default is 1
s1 us.store # default is s1.us, s2.us etc
}
cn {
availability 2 # High availability is 2 more servers - default is 1
ha1 cn.ha_lupin # Optional server names otherwise default names ha1, ha2 etc
ha2 cn.ha_posh
balance 4 # Load balancers is 2 or more servers - default is 1
lb1 cn.lb1.shop # Optional names of servers otherwise name is lb1, lb2 etc
lb2 cn.lb2.directory
lb3 cn.lb3.cart
lb4 cn.lb4.mysql
servers 1 # additional servers - default is 1
s1 cn.store # default is s1.cn, s2.cn etc
}
research {
}
next_block_chain e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
- The user generates configuration request data (less the first and last line initially). The configuration sever then combines the data with previous block chain SHA256 checksum and then creates next checksum over the combined data. In this way the block chain cannot be corrupted. The blocks themselves are created and distributed from a secure https server or an even more secure private certificate authority server (whose certificate the user needs to validate and accept once manually to maintain the chain of trust). The block chain server will confirm any valid SHA256 checksums it has issued and thereby maintain the chain of trust whenever validity of a block is queried. The servers reading the block chain and keeping records of configuration changes in a distributed ledger need only verify the last block with the block chain server as all the previous blocks can be checked by the local server up the point where it needs to check another block which has been detached from the block chain due to lost or corrupted blocks.
- Proof of configuration changes, uptime, and other statistics are formatted in similar blocks with the SHA256 checksums from the servers and sent back to billing servers which then create reliable bills and an audit trail.
- To allow verification to scale, a list of (decentralized) trusted servers are added. (By default the first server on the list assumed to be the originator of the block.)
previous_block_chain cc19c6c09cafe004db004ec10569ccb6bc859fd5874960897f558e1ef22eb8b4
# This date stamp added to the server name and next block chain checksum for full URL
# e.g. https://lupin.com:8080/2019/05/01/22/15/e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
# - 404 means not validated, anything else can mean validation
verify 2019/05/01/22/15
lupin.com:8080
bc_verify
# domain to access the servers - so the store servers become s1.uk.store.ponytail.com and s1.cn.store.ponytail.com
domain ponytail.com
..
next_block_chain e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
- The Hypercube Block Chain (TM) Technology is intentionally architectured free of block chain excesses such as bitcoin mining, high cost gate keepers, and walled gardens.
- It is very low energy system and suitable for IoT. We will soon be releasing open source tools to developers.
- The ledgers are hard to modify and easy to verify (without mining) by all servers invited to be in the trusted verification system (as well as by independent public ledger monitors outside of the walled garden who are given access to the block chains and funds to maintain duplicate copies of the ledger).
- Trust in the system depends on how well you trust the organizations you are dealing with, as well as how much you trust the public key encryption system.
- A famous example of public key encryption system failure of trust is DigiNotar.
- We provide private certificate authority to deal with this kind of failure and ultimately put all trust between you and the person you are dealing with, without anything in the middle.
- The blocks are https encrypted when traveling between servers when using the real Internet.
- The blocks can transport any information such as configuration, notifications, binary data, verification, inventory, payments, dispersing grants, tracking information etc.
- The blocks can be inspected by AI decision making systems to arrive at conclusions way beyond any mortals are able to arrive at in a short enough period of time.
- With the block chain system we architecture, Hypercube servers will be able to deal with any type of transaction internationally at low cost for any government agency.
- We will open source our entire block chain technology so you can benefit from using it.
Block Chain For Government Use
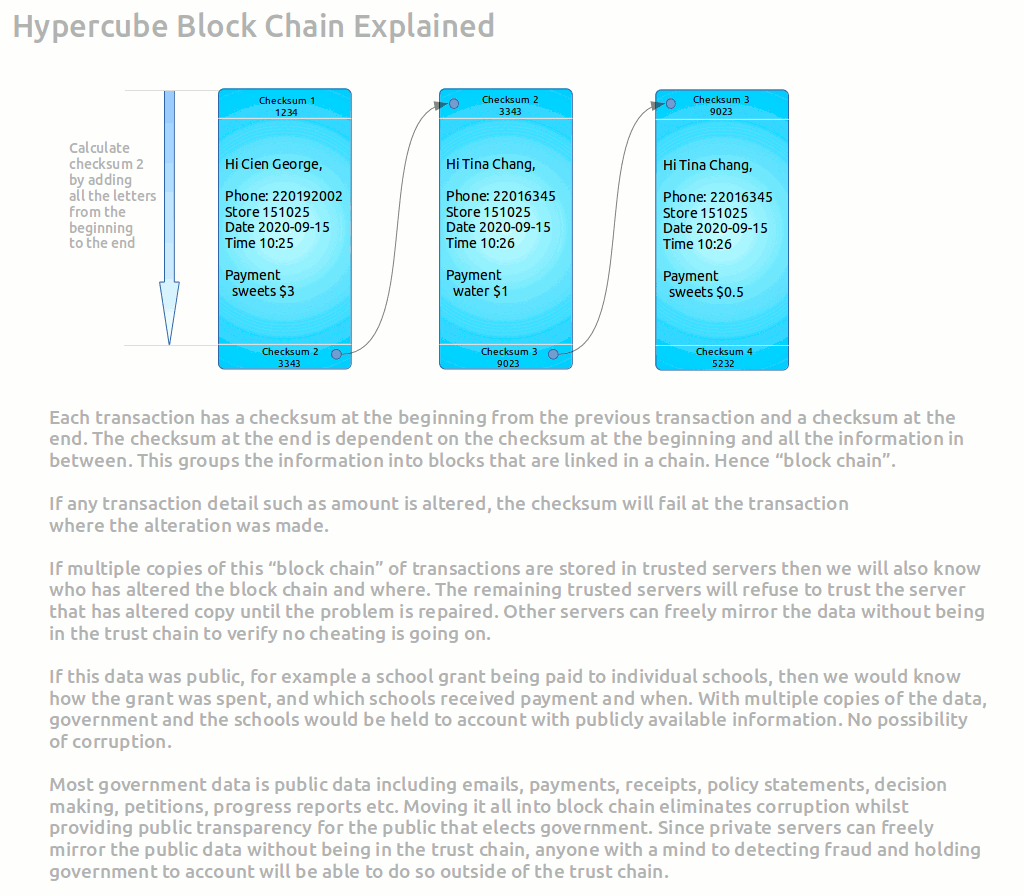
- The diagram shows in a simplified graphical form how block chains work.
- Each transaction has a checksum at the beginning from previous record, and a checksum calculated from the previous checksum and the new data.
- These blocks of data are linked because of the dependency of the checksum on previous checksums.
- There are many ways to calculate checksum - some are simple such as adding all the characters together which are easy to defeat - but others such SHA256 is practically impossible to defeat.
- If any data is altered such as amount, then we would know where the data was altered because the checksum will not match.
- The data is normally held as copies in many servers.
- All we would have to do is calculate each checksum with our local copy of the data to see who has a problem copy by checking with other servers their checksums.
- This checksum is called a key.
- You need to be aware that this key makes block chain corruption and fraud traceable which has the 'establishment' spooked looking over their shoulders all the time whenever block chain is mentioned. A cool reception to introducing block chain ideas or trying force keys (and/or its underlying data) to be put under private control is a good indicator that corruption is endemic within the organization 😀. Since the data cannot be corrupted, the data and the keys can be put up on public servers for all to see and double check its integrity at all times with perfect global knowledge that no one can alter content.
- So in reality what it actually means is that block chain companies, government funded organizations, banks, software houses to private individuals that are not reliant on fraud and corruption are seeing an exponential future 😀
Key Management
- A lot of block chain systems have problems with key management.
- The Hypercube Block Chain publishes all keys by having time and date stamps in each record and using https servers to check a key, eliminating trust and management in one fell swoop.
- Each server can generate all the keys from local copy of the data manually just once for checking credentials.
- Each server does not have to check every key with a trusted server.
- They check the first and last key with a trusted server to know if there is a problem in the middle of any block chain of data.
- If there is, the server checks with other trusted servers until the problem is isolated to the server and copy of the data which has been altered and flag it up for all to see.
- Quantum computers to supercomputers cannot defeat 'block chain security'. The keys are public, so there is nothing to defeat. Each new member of the chain is dependent on the previous member, of which there are multiple copies and so there is nothing that can be done to forcefully change all copies other than break into each computer and alter them simultaneously - but that would be impossible with so many public peers to anonymous peers keeping copies of the data and working with it to create new records on the fly.
Solving Double Spend Problems With Block Chain
- The problem with digital currency is that there are endless ways to double spend.
- With block chain, there is no way to double spend.
- Double spending is a way to spend the same funds more than once without being detected.
- There is also the problem of overspending. The two problems are separate.
- To solve double spending, each server checks funds available against local copy, and then authorizes fund deduction and stores it as a new record chained with other transactions using block chain checksum. This information percolates to other distributed servers which then recalculate the account totals.
- It is impossible to double spend with this system because all servers record spend information and update the distributed ledger.
- It is possible to over spend with this system if there are no circuit breakers.
- A circuit breaker is simply waiting time for all distributed servers to catch up. Without a circuit breaker, it would be possible to spend over the account limit before the over spend is discovered. With a circuit breaker of lets say 3 seconds for all servers to synchronize, the deduction is checked against the previous time stamp and will get authorized if more than 3 seconds has elapsed if no new transactions took place within those 3 seconds. Accepting funds requires no circuit breakers. Large balances with small deductions require no circuit breakers. The circuit breakers need only activate when balances are low and possibility of overspend is high and at the same time overspend is not desirable. Overspend is manageable if overdraft facility is available. Once overdrawn all transactions are subject to circuit breaker checks.
- To check for distributed overspend attacks, the system could simply wait for 1 second longer than the circuit breaker time, and check if any transactions other than the one just about to be authorized have been added before sending out confirmation of a transaction. For users such as individuals using a checkout or an online shopping service, it is physically impossible to place two orders withing 4 seconds. So when the overspend attack is detected, the account can be locked immediately.
Managing Government Data
- Government is the largest source of data in any country.
- The bulk of government data is public information.
- Distributed block chain is the only way to manage such infinite sources of data.
- Hypercubes can manage billions of transactions per day with the Hypercube version of block chain as described above.
AI Introspection of Government Data
- The Hypercube system manages to release all data publicly and in a form that is trusted.
- Any private or trusted server can join the system and download all the data it needs to perform AI report generation and decision making.
- This type of AI is not prone to corruption with corrupted data because the development tools will be open sourced and everyone can access public data in a trusted way to create AI programs.
- For most of the data, 'Data Protection' and deletion of historic data is not a valid way to handle data because the data is stored in trusted block chain format generated by the public and its government, which means it is for the large part public.
- For most of the data, there is nothing to hide. Thus AI can make absolutely reliable summaries daily on the workings of government and our society for better planning.
- We can for example log all records of traffic sensors in block chain format. This data is not structured. (Meaning each device will use its own text data format, and each device could volunteer specific information in a different format requiring different parsers to recognize the data we want. The issue being, the sensors have no idea what data is useful to whom and when.)
- If this information is public and if AI can freely access the data and trust it, then it can be used for good to filter the data and show us how best to manage traffic.
- Traffic models can be independently created from unstructured data without making the data its built on proprietary so that anyone can lend a helping hand to solve problems using their own AI machines and verify the conclusions independently.
Hypercube Data Processing Solution
- The reasons for using Hypercube are:
- Hypercube is a 3D wired data center and cloud solution that allows 10x the compactness of data center compared to flat data center.
- 3D wired technology is predicted to exist at about this time from the Technological Singularity Curve.
- We use 10% energy to achieve more than 90% of the performance of energy hungry data centers.
- We exploit DDR RAM paging speed limitation to make it happen.
- Our data center processes 900% more data per unit of volume, time and electrical power than a high energy flat data center.
- These are big claims when experiencing it first time. OK to understand the logic when you create both hardware and software.
- For the average data scientist or management, it is easy to push for a big flat 3D energy hungry data center cloud solution but here we apply intervention to change your mind.
- To find out about point no.1 see Hypercube Geometry
- To find out about point no.4 see DDR Paging Speed Limit
- For this tender, our system is designed to measure crowd flow with a micro cloud and this is how we intend to do it: Hypercube crowd flow measurement system
Micro Data Center and Hypercube Cloud Solution
- A large amount of data cannot be sent to some one else's cloud for security reasons. Hypercubes offer a way to assemble immense computing power in a tiny volume with very little training.
- With less than a day of training you can order the Hypercube data center parts and assemble a 1000 processor data center in less than 2 days. They come with cloud software just like any other cloud solutions.
- The boards are practically same as the open source Hypercube IoT prototyping boards - just bigger.
- So if you have used Hypercube IoT boards already, assembling the data center to go with your solution is a breeze.
- These servers can connect to tens of thousands of IoT devices and log their data. And you can then write code for it and start testing solutions.
- But the clever part is that you can do it all in the space of about 3 or 4 desks.
- You can test the servers, test the IoT devices, debug it, all within the confines of your office knowing that none of the data is reaching the real cloud where it could get compromised.
- This is what we sell well we talk about micro Hypercube Data Center.
- It is a way to make the future happen inside your office without having to sign big out sourcing contracts.
Security and Degraded IT experience
- Yesterday hacking was all about a little mischief.
- Today economic hacking is all about degrading your IT experience and staying hidden while you are being subjugated, and you or your company's economic value eroded away.
- This means file being corrupted and deleted, emails not being sent or received, configuration changes to software to create IT support demand and increased psychological stress.
- It used to be changing file formats so that old file formats became incompatible instantly putting all your past work and history out of reach to make you start all over again. But users got wise to this and refuse to buy such software. So the new ways have been developed that are far more subtle and subversive.
- You could for example locate your files into the cloud only to see it shared and drive all your customers away, or the cloud company goes bust taking your data with them.
- A way to get around this economic hacking is to have your own micro data center and multiple security systems that report issues in numerous different ways because there are so many more servers monitoring each other and server network activity so that no single point of failure exists.
- Even if single accounts could be hacked, what those accounts are doing could be monitored in a micro data center because there are numerous servers that can check all the different types of activity to pick out unusual activity.
- While this required a lot of people resources in the past, all the important detail can now be automated through server arrays to create a report detailing all suspicious activity that has been logged.
- The entire packet processing system from the router is custom inside a Hypercube and capable of logging packet details to denying packet level permission for unusual activity by default. Multiple accounts across multiple servers keep the entire system in a state of flux such that any intruder will find hard to attack every bit of the system simultaneously. Simple acts such as gathering information through a connection is deemed a suspicious activity allowing reports to be generated to identify compromised accounts that are engaged in suspicious activity.
- Today only a big data center can do this. With Hypercubes, the micro data center array sits in your office in a very small room. It can get updated with multi-server security updates and features as new methods are developed, ensuring that your business doesn't suffer from degraded IT experience and lost files to corrupted data from hackers that are focused and value staying hidden. And if discovered, they have so many well rehearsed plausible deniability responses that will make your defence look out of touch.
- Hypercubes are arrays of servers where it is viable to create honey pots and misleading information as a service for hackers to hack into and not know they are downloading it and using the misinformation which would be easy to detect once they go public, and thus respond to, to demolish any plausible deniability responses. Such techniques have worked in the past for nation states such as France during elections. Traditionally it requires a team to implement, but with AI and a little help from Hypercube server arrays, this is a very low cost solution for medium size businesses.
- Measuring how much IT is degraded daily is the key to understanding overall health of the business. Hypercubes have ample storage to back up local disks in full and perform binary comparisons to file level comparisons of disks to determine where degradation is taking place and how many files have been targeted. By measuring subtle changes in the files, and seeing it replicated across machines allows a degradation index to be worked out to determine which departments have become targets. The usual target is sales and accounts, so we can keep changing PCs back and forth at the bit level, or the entire disk level, or create fake workstations to honey pots to keep degradation at bay from real operations and direct attackers into time wasting false effort.
Barcode and RFID based Stock Management System
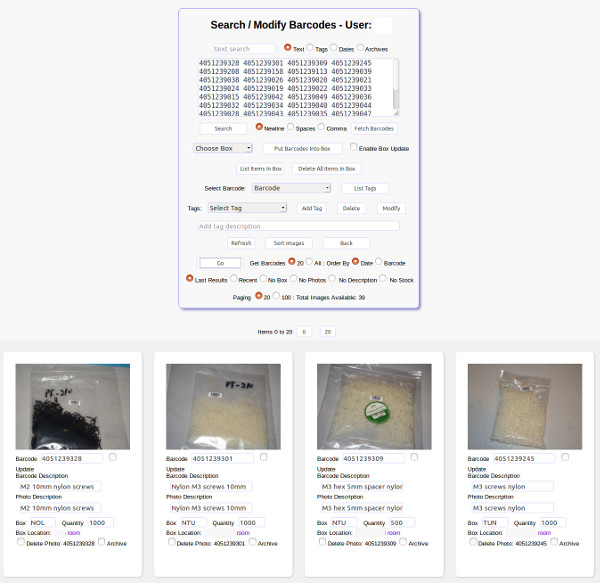
- Using Hypercube developer system, we are making excellent progress with developing a barcode and RFID based inventory management system.
- The Hypercube data center PCs have all the big software running Python, MySQL, PHP and Apache for the multi-user web based inventory management system.
- The smaller items such as firmware we have ready for IoT boards.
- We already have a vision system working that can read barcodes and QR Codes and bring up the relevant web pages in the inventory management system.
- Now we add RFID reader and digital scale with just 2 days of work using the IoT versions of the Hypercube. This special weighing machine allows contactless identification of bags and then the digital scales record the weight to determine the quantity and all connected through web interfaces to update automatically.
- Inventory management becomes just that one step easier to implement.
- Most of these projects that user Hypercube IoT boards will be open sourced at some stage.
Update 2019-04-15
- A dozen new motherboards arrive to construct next generation of Hypercube Servers.
Update 2019-04-17
- Some of the new motherboards configured into arrays for development of services.
- This a temporary measure while metal version of the Hypercubes are built.
Update 2019-05-19
- A second cluster built to test software configurable DHCP server and packet filtering with custom PC router.
- Working. When its finished, email configurations through block chain certificates and update server clusters.
- The entire Hypercube server cluster is managed from end to end with software configurable routers, high availability servers, and then load balancing servers, and then the servers.
- You send configuration sets through email which is distributed through block chain mechanism, to the servers that auto configure on demand according to which ever sets you choose.
Update 2019-06-03
- The second cluster now has routers configured from configuration files.
- This will allow block chain control of the router configurations to dynamically reconfigure on demand
- The idea is to avoid getting hacked, and if hackers do manage to get in, from within or without, the routers reconfigure isolating the problem and cutting off the affected servers and connections on demand through block chain.
Update 2019-07-03
- DNS server with firewall software ready.
- The aim is to mix high workload and low work load servers.
- Assume each data link available to a Hypercube with 12 servers is through 1gbit Internet links.
- Higher speed links do not result in greater throughput rates for average Internet traffic
- The precise reason in 2019 is down to the way servers are built. Disk head movement speeds and DDR paging speed limits needs to improve.
- Until such time, it is more correct to use split high gbit links such as 10gbit and 100gbit into separate 1gbit links with a switch first.
- The switch needs to have high bandwidth backplane able to cope with realistic amount of high volumes of average Internet traffic.
- Twelve high work load servers in one Hypercube will easily overwhelm a 1gbit link. Just one SSD can produce several hundred megabytes of data per second while the 1gbit link can only handle 100MB. While 12 servers can parallel up to produce minimum 120MB of data even with maximum DDR page faults. In this type of architecture, each 1gbit link needs its own external facing IP address to provide high data throughput. Think of a government web site for example and buying a public IP address range to serve huge amounts of data.
- More than 300 server low work load archive storage on the other hand may only need 1gbit link because there is never going to be a demand on all servers at once.
- Having DNS server and firewall architectured into the Hypercube allows real world configurations to be managed easily so that high work load and low workload servers are mixed and managed without having to over specify or under specify server requirements and the energy requirements needed power the server rooms. We easily skip past disk head movement speed issues and DDR paging speed limits by paralleling up servers to totally saturate all available data links with data through the use of DNS server and firewalls built into Hypercubes. All for about 10W per server. Big data centers can hardly begin to imagine such productivity without use of 1kW of power per server and extremely expensive routers and human resources to glue it together.
Update 2019-07-25
- Now we see need for distributed block chain driven single sign on and start implementing it.
- We also see need for shopping cart to become distributed block chain driven which will be much faster for checkout collating inventory and preventing excess ordering of items in a distributed flash sale.
|