|
Home Page
Six Transistor Cache
Investors
Launch Date
Contacts
Terms and Conditions
_________________________
|
Hypercube Cloud & Data Center
Hypercubes Cloud and Hypercube Data Center scalable to suit IoT projects to mega scale projects
Related
Hypercube Clouds and Data Center
- Hypercubes good for small hobby projects to large supercomputing arrays for 3D wired Data Center. Below is a working ARM SoC supercomputer Hypercube which pushes Data Center technology to new heights.

- The power supplies and 16Gbit back plane switch is built into the Hypercube
- The above Hypercube is 44 core supercomputer array with SSDs running Linux with Apache web hosting and ftp upload for IoT cameras. Densely stacked 3D arrays of these Hypercubes is what makes a Hypercube Data Center (TM). The key difference between computers arranged in old fashioned flat data center approaches and Hypercube approach is that all the PCs in a Hypercube are wired in 3D allowing compact data centers to be built.
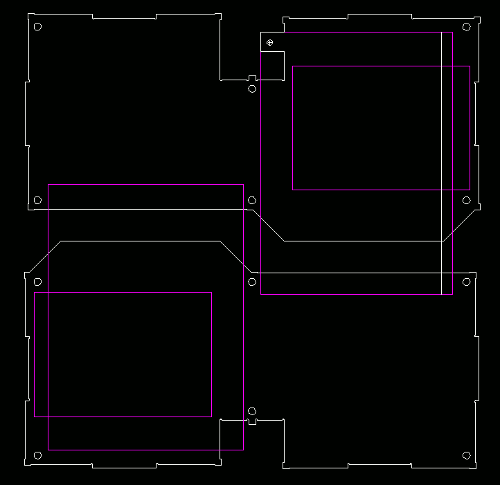
- Hypercube Geometry page explains how the wiring is possible by partition 3D space into hardware spaced and non-intersecting conduit spaces.
- Hypercube locks show how quick release clips help assemble giant structures in minutes.
- This is the fastest scalable server room technology in the world merging IoT projects and micro Hypercube Data Center into one seamless technology inside research lab in one place. The servers are running Linux and Python scripts.
Why Linux?
- Linux is open source and the source code is readily downloadable and can be modified.
- Then why not write a virus?
- If you could write a virus for Linux, you deserve a medal, and get great job offers!!
- Because the source code is out in the open everyone is able to look at the code, and repair all problems and post updates to the maintainers who then incorporate it into the main source code.
- So in short, it is extremely hard to write any kind of virus for Linux.
- You would have to be better than the entire Linux community to write such code.
- There are more engineers maintaining Linux and open source code than for any other operating system.
- Thus Linux code is repaired within hours normally if a problem is found.
- Because the source code is free to download and use, vast farms of computers compile it and test it against all kind of errors and compatibility for drivers and other software.
- So while private operating systems are closed and cannot be tested or repaired in a timely way, Linux is used by all the top companies around the world for its servers.
- If you are learning some other operating system, you can't have a top job in top global companies heavily reliant on servers which includes banks, stock trading companies, social media companies, online retailers, search companies to IoT companies. You need Linux.
- Linux for desktop use has the same benefits as Linux servers, but there is a steep learning curve if you first learned someone else's private operating system to switch to Linux or to any other private operating system from that first system. Naturally private OS vendors give it away for nearly free and subsidize it with additional education software so that you are hooked at an early age. But you are wasting your own time, unable to get a top job with it, using up resources and diminishing a bright future if you are hooked and unable to change. More than likely you are buying pirated copies of the private OS, and using pirated copies of proprietary software to get the edge. Many of these products are infected with virus or has vulnerabilities for which there are not enough paid engineers to repair it. The trend in malware is to degrade your software and computing experience which means you waste a lot of time becoming angry with your computer and do less work. While open source has tens of thousands of package free of charge with source code that has all its vulnerabilities addressed at an early stage. If you need to improve it, you can request it or contribute the code yourself. And your data and computing experience is not degraded with time allowing you to build on what you built before instead of getting stuck in loops repeatedly trying to recover from a crashed or degraded position.
- If your life is full of misery stories filled with degraded computing experience, then you finally realize your time is precious and you need to learn Linux.
- If you want to scale solutions and become a global force, stop drinking cool aid offered by proprietary vendors and start downloading and compiling Linux to learn how empires are built. Only after that can you become as big as Google, Amazon, Alibaba, Facebook, London Stock Exchange etc because they all run on Linux and total ownership of the code that goes into their servers to prevent outsiders taking control of your infrastructure with spurious billing as soon as you start making money.
Why a private cloud?
- Its not always possible to trust Big Data to the Cloud - use a micro Hypercube Data Center to keep data private whilst bringing the data processing in house to crunch the data locally and save physical cash.
- All big companies reliant on Internet must do it or hand a large chunk of cash flow to the cloud vendors.
- Data is more valuable than oil which is why you must protect all that you own and create all the key knowledge indexes from that data locally because that is timely business insight which is more precious than data itself.
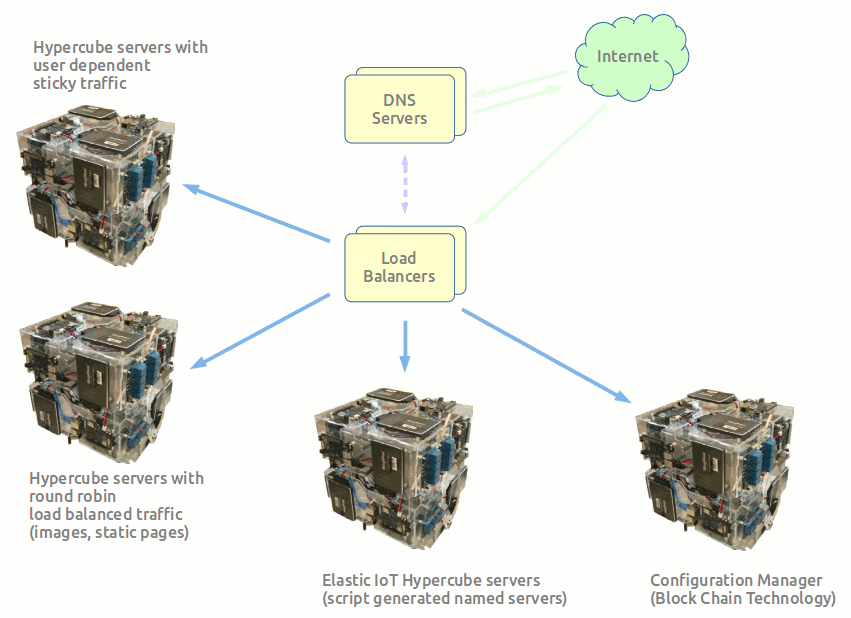
- Each micro Hypercube Data Center system comes with its own DNS servers that route traffic to own load balancers which then route the traffic to user dependent sticky traffic to dedicated servers, round robin load balanced traffic to image + static content servers, and elastic servers that are livened up on demand by scripts to service IoT devices, surges in traffic, and reconfigurable servers that reconfigure as customers come and go. The scripts change the DNS servers on the fly to give names to all elastic servers and IoT servers for developers with accounts on the system that then avoids them having to hard coding machine specific information.
- The configuration management implement with block chain technology.
- The DNS servers working.
- Load balancing working.
- For IoT and elastic servers, we will make available simple text files to fill in to commandeer as many servers and you will need to complete a task.
- Each elastic server is commandeered in 30 minute chunks and automatically gets removed if a keep alive signal is not sent with 30 minutes.
- Numerous different ways to send the keep alive signal - the API is as simple as a Python module that is invoked or it can be as simple as touching a file to change timestamp on a file if using other languages.
- In this way, you will only pay for each server that is doing real work and instantly stop paying for resources not used.
- Functions such as replicating servers, data, hosts, ports, databases, are all scripted and taken from simple text files.
- These text files can themselves be automatically generated by Python scripts to any language that outputs simple text files.
- The configuration files can be held in separate directories and activated as needed reducing the need for human intervention.
- For maximum security, the scripts allow the configuration files to change servers every 30 minutes. This just makes it hard to identify a selected server for a specific attack.
- Physical security is improved with 3D wired Hypercube servers as its impossible to get easy access to machines buried deep in a 3D structure without disconnecting a large number of security alarms.
- For places like hospitals, care homes to modern Industry 4.0 factories, Hypercube is designed to integrate server technology and the logging devices such as the many IoT boards being developed into one unbeatable 3D wired system which has never been possible before, all connected together with symmetric gigabit fiber Internet and 5G technologies.
- Typically the machines are stacked into a 3D array around scaffolding structures, and then the scaffolding is removed leaving behind a 3D packed Hypercube Data Center. The Data Center can be tightly packed into a 3D structure to occupy every part of a building or a machine or a structure, and then wired in 3D to make a network of machines like those found in Data Centers. The power supplies are in their own Hypercube boards, and they can come with distributed batteries for resilience against power outages. (See for example Hypercube Lithium Prototyping Board.)
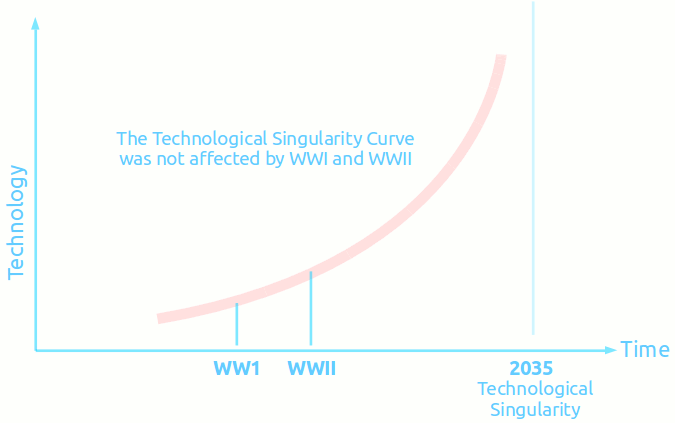
- Ray Kurzweil is an incredible genius who noted that human technology is evolving at an exponential path - most notably information technology. If this pace were to continue then by around 2035 technological evolution would become exponential and vertical. But there is currently a problem with the predictions. We are supposed to be in the era of 3D computer chips today as Moore's Law is tailing off and unable to keep up with demand.
- Incredibly Hypercubes are positioned just at this precise moment in time to address the need for 3D wired computers. A 3D wired Hypercube Data Center can get over the main technical limitations of Moore's Law tailoring off by building 3D wired computers. .
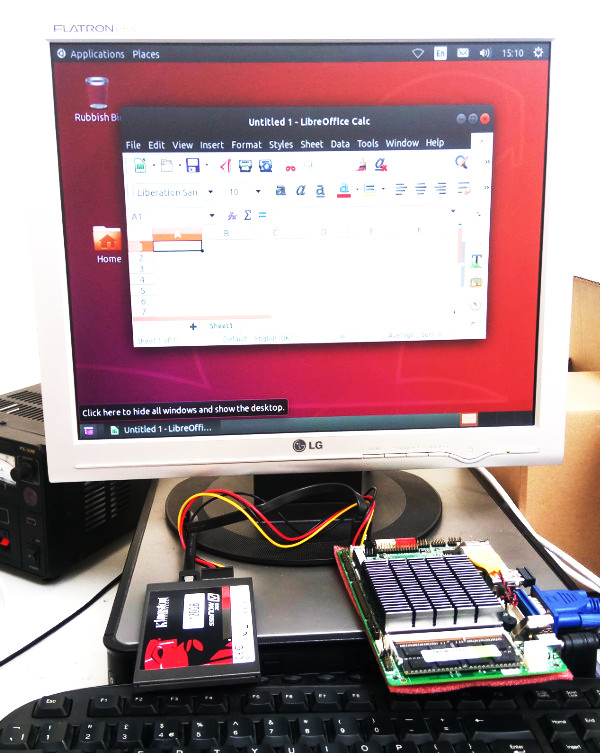
- The first picture is what Hypercube PCBs look like when assembled into project in minutes (see Hypercube Power Distribution Board). More variety of boards can be wired together in 3D to make complete systems.
- Each Hypercube requires 12Gbits of network capacity (theoretical maximum). The combined data throughput from SSD storage devices easily capable of overwhelming 12 Gbits networking capacity so the data is buffered in RAM and contended to the network which implies the CPUs are rarely if ever 100% busy.
Intel Hypercube Supercomputer
- The design is taking shape - a low energy (10W) board has been chosen.
- Ubuntu 18.04 now boots on the low energy Intel board
- Next steps are designing Hypercube PCB for dual redundant power, storage, and remote power cycle reboot through a RS485 network
- This board digs into the conduit channel a little, but OK for this application.
Hypercube Micro Data Centers
- With the increasing overheads of maintaining big machines and research and develop new machines such as ships, trains, planes, mining machines, Hyperloop pods etc, there is a need for those machines to have on board a Hypercube Micro Data Center.
- The purpose of the Hypercube Micro Data Center is to process images, vibration sensor data, wind, thermal data and so on in one place in a consistent way that absorbs modern sensor arrays into a big machine to manage it and maintain it better and reduce operational costs with planned maintenance and sensor based maintenance.
- Sensors such as vibration sensors, thermal sensors, noise sensors as well as battery packs etc require small embedded boards while data processing require big PC scale processors and storage. All these boards are mixed into compact Hypercube array in a seamless system arranged in a 3D wired computational structure that follows the contours of the small spaces available inside machines.
- Micro Data Centers speed up AI fusion work many times over by placing data center and sensor systems together into small spaces available inside machines such as Hyperloop pods to self driving vehicles that are being developed. These micro data centers help towards making projects safer, and use AI to make faster decisions and better decisions. Why is this happening now? Because processing and storage has become cheap, the AI ecosystem is larger, and Hypercubes enable 3D wired computational structures to be made where previously it was all 19" rack solutions that are cumbersome. First, the data collection is addressed by embedded CPUs, then training is performed using on board AI using bigger processors, then inference is made based on new data gathered with sensors in situ to control the machines. Data is often located across many sources and can lag if its in the cloud, thus having the data on board speeds up local processing to know what is possible without projects being compromised by slow cloud lag. AI data volumes are huge and growing, and data velocity issues grind projects to a halt requiring micro data center solution that are adaptable to power these workloads that scale.
Cloud Latency Busting
- Could Latency Busting (CLB) machines bring the power of AI right next to your physical presence without the latency. Data can become precious and cannot be downloaded or uploaded for security reasons, or in a timely way to the cloud. These kinds of restrictions kill projects in no time. The answer is to bring the cloud to your application and eliminate the latency. Sometime the task is to figure out an optimum position from current financial trend for example. Other times, its to find out where next to drill from the raw data. There is no time for data uploading and downloading. The opportunity is time sensitive. And you need CLB Hypercube there and then. Which we can do. A 1000 CPUs Hypercube array with each processing running at several GHz would take up about 4 desk spaces and consume about 5kw. Having your own CLB Hypercube Array defines who your are in an organization and how important your work is to your organization.
Progress

- This is the relay board to turn on each individual CPU or arrays of CPUs in Hypercube format. It allows 12 systems to be turned on and off as needed. Typically in a Data Center unused resources are switched off to save power. Giant collections of computers are brought on line as needed by an independent network of embedded computer systems that monitor power, temperature, and software conditions of the CPUs. Hacked CPUs to crashed CPUs are rebooted independently of the server CPUs.
- A variant of this board with length tuned tracks switches between SATA devices to allow a master to take control of slave disks, reformat and re-install operating system and reboot slave computers.
- We need all this capability as Hypercube Data Center servers once installed into a 3D matrix are not expected to be recovered until their service life has expired. If an item goes faulty, it is simply switched off and left in the array until 18 months or so maximum has elapsed at which time new technology arrives with double capability and it becomes obligatory to replace.
- Currently these ARM CPUs have been tested and found to be running for 6 months average without need for reboot or air conditioned rooms. This form of resilience testing is intentional as data centers that we make are not expected to ready made with air conditioned rooms that cost a lot in terms of energy bills and super sized AC units. We have servers that have been running for several years under these test conditions.
- These secondary systems based on embedded CPUs are not usually hackable because they run from independent networks that should not be connected for remote access.
- Every day tasks such as backing up are run through the normal computing facilities available through each server and the Linux operating system running within it.
Hypercube Embedded Supercomputer Arrays Are Faster Than Intel i9 CPUs Server Arrays for AI projects
- With a number of caveats that apply :)
- The problems with Intel (and ARM SoC) begin and end at DDR DRAM cycle times.
- No matter how much the double data rate transfer speeds are, those rely on accessing memory sequentially from the current page in hundreds of picoseconds.
- But page sizes are small - around 4K. So when its time to change page, the DDR DRAM must move to another page and this is where the problems hit like a ton of bricks.
- It takes tens of nanoseconds. There are so many variants, but a safe round number to talk of is 50ns. But 50ns is 20MHz!!!!!!!!!!!! More info
- So if a program has to continually jump around, the actual speed of the $1000 Intel i9 CPU drops down to 20MHz!!!!!!!!!!
- This is true even if using DDR5!!!!!!!!
- So what are you actually paying for when buying $1000 CPU?
- You are paying for those block transfers in current page at gigabytes per second burst speeds.
- But if your software is jumping all around the address space causing page change, which it can do with graphics software, games software and database query operations, then your speeds are 20MHz!!
- So you mitigate graphics rendering with graphics accelerator for pixel rendering, improve games with offloading gaming algorithms into the graphics controller.
- But what about database? Nope!! There are no such off the shelf things at the moment.
- So you do a query, you are unlikely see improvement over a year 2000 PC. But a lot of that is down to mechanical head movement of hard disk.
- So you improve on that by adding an SSD which will speed it up. But once again, take care, many of these SSDs can only do around 1000 operations per second (which is constantly improving).
- So you finally got a i9 running like a 20MHz PC thats accessing disk 1000 times a second. What chance of trawling through terrabytes of data with that?
- Absolutely none. The way its done is to partition the data and farm it out to a number of PCs and or reduce the amount of data that each query has to deal with.
- With all that in mind, how do you build AI supercomputer?
- To build the AI supercomputer you need Hypercube Embedded Supercomputer Array with all these boards with more to come :)
- Instead of using Intel CPUs, it is far better to use 100MHz to 400MHz embedded CPUs with internal flash and RAM. These can clock memory at speeds of 50MHz which is noticeably faster than DDR speed limit of 20MHz!!!
- But there is so little of it, that it cannot run big software packages. Typically you got 1 MB of memory instead of GBytes.
- If they get any bigger with current technology, then likely they get slower.
- But AI is all about coding ideas into numbers and making decisions. And distributing those decision making centers into an array of CPUs. Typically you can make around 100,000 decisions per second with each CPU allowing each CPU to execute around 1000 instructions per decision average (which includes access to 50MHz RAM, and register operations).
- So if you could get 12 embedded CPUs making decisions, you are making around 1 million decisions per second with software with software that is jumping around all over the place in the decision making code.
- The only things that can catch it is an FPGA. But FPGA are not running C like code, and so its not a generic problem solver as complexity grows.
- Typically what the embedded supercomputer is trying to solve for real world autonomous systems that carry its own AI are
- Inputs from sensors such as GPS, Lidar etc and looking up what behavior it should follow next
- Converting sounds and vibrations to Fourier transform and running recognition software over it
- Converting vision signals into recognition that can be meaningfully communicated to other systems such as actuators
- At all times, we are limiting ourselves to reduce the need for FPGAs until they are critical and time saving.
- Hypercube board with FPGA will be available to implement FPGA solutions for sub-systems.
- Also Hypercube boards with low energy ARM SoCs will also be available. They are good for much more data intensive applications such as synthesizing speech.
- The ARM SoCs also have the 20MHz limit due to the use of DDR, but their power consumption can be held below 5W for 1GHz operation so we can use many more of them in parallel for data processing. Higher speed operations such as controlling motors and fast decision making are implemented with embedded CPUs.
- By combining Hypercube embedded controller boards, Hypercube FPGA boards and Hypercube ARM SoC boards into the Hypercube arrays, the best of all worlds are combined into a self contained system suitable for making complete AI machines that need to carry its AI on board such as robots, autonomous cars, autonomous delivery systems and so on.
Hypercube High Security Data Processing Environment
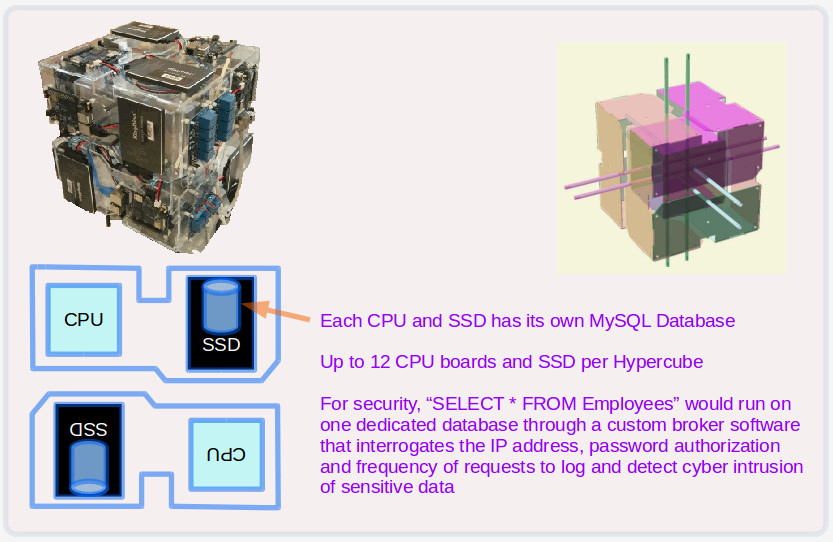
- Hypercubes contain 12 CPU boards in a full cube, with each running Linux on an SSD.
- Each Hypercube CPU board run its own MySQL database (and web server) by default.
- If you are writing high security applications, tables are partitioned into different CPU boards to operate on data faster in parallel.
- Partitioning data also enforces security boundaries for each table. For example "SELECT * FROM Employees" would be run by one CPU to retrieve personal data such name, address age and so on, an Employee Data ID for data stored on that machine, and this is separate from all other data about the employee which will be held in a different CPU board and disk referenced by Employee Data ID. If a hacker managed to log in and steal all the other tables and from all the other CPU boards, there is likely nothing there to identify a specific employee. Access to employee data would be implemented by a broker program that first logs who is asking for Employee data, and check the machine IP address, and some password, which makes it a lot more difficult to extract personal information directly out of the CPU containing employee personal data.
- Partitioning the data is easy in a Hypercube Cloud because there are a lot more real CPUs available with physically separate disks to prevent hackers direct easy access to data without being logged.
- Broker programs check important details such as which machines and IP addresses are authorized to access specific data, check the frequency of the data being withdrawn (to detect siphoning by insiders), check for employee records that are intentionally fake being accessed to spot hacker activity. All because Hypercubes have enormous numbers of low energy CPUs at its disposal to process big data.
- Each Linux disk can also be encrypted such that if the physical disk was stolen, its of no use to anyone. (Encryption slows down disk operations, so it is used only on the most valuable data such as personal records.)
2018-09-25
- 1 Gbit symmetric fiber Internet ordered
- Soon we will have our Hypercube Servers running on it with Linux as operating system and numerous applications and projects.
- All the material that is about to be open sourced will be served from Hypercube Servers with the anticipated TB per day downloads
- All the training material will be available for students to learn embedded Linux, and other essential skills such as KiCAD, Python, C, SQL, PHP that relates to the work we do.
2019-01-09
- The 19" 12U rack arrives for gbit Internet link.
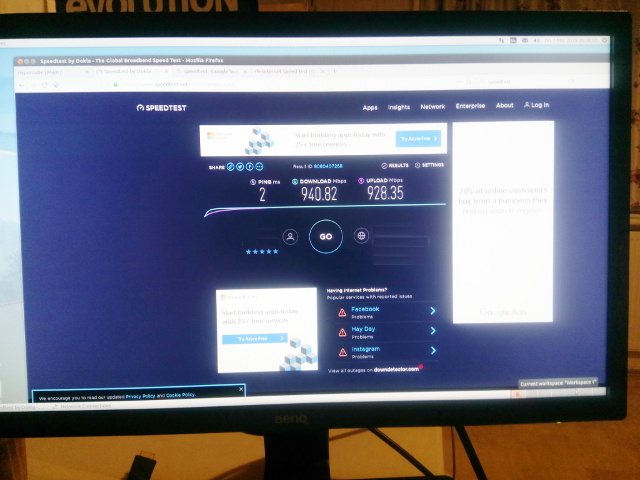
2019-03-07
- The 1gbit symmetric fiber connection is now in for testing
2019-03-12
- China investor announces they have placed orders for PC boards to build Hypercubes
2019-09-12
- These are final working prototypes for the locks to lock Hypercubes together
2019-11-11
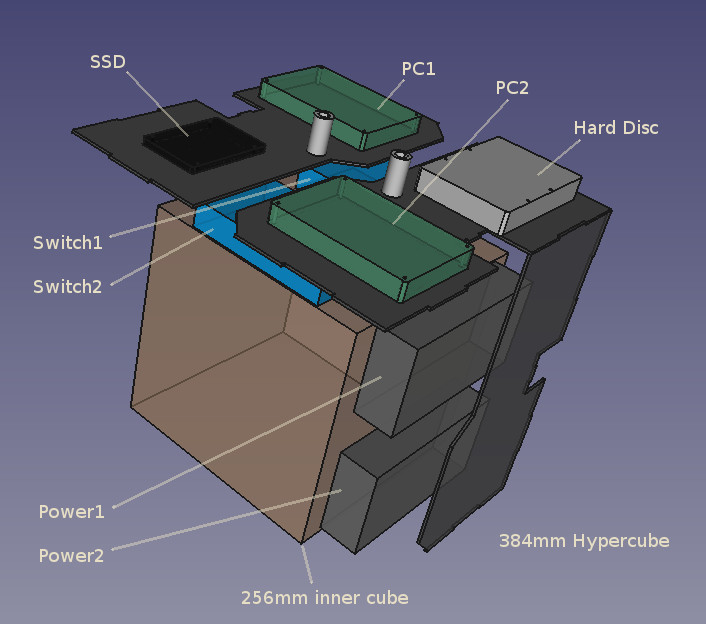
- Parametric Hypercube Server design under way.
- This particular version has dual switches, dual power supplies and option to fit mSATA, SATA and/or hard disc for the servers.
- One of the PCs will behave as load balancing router allowing fully customizable servers.
2020-01-08
- The fiber optic SFP modules arrive for motherboards
- We developing Hypercube with all servers running at 1gbit speed using fiber motherboards, routers, firewalls, load balancers and high availability server configurations.
Related
|